Decision Trees
Overview
A Decision Tree is a flowchart-like structure used for decision-making and predictive modeling. Each internal node represents a test on an attribute, each branch denotes the outcome of the test, and each leaf node represents a class label or decision.
This hierarchical structure facilitates both classification and regression tasks, making it a versatile tool in various domains.
Decision Trees are favoured for their interpretability and simplicity. They allow users to visualize the decision-making process, making complex decisions more manageable and transparent.
Origin
The concept of Decision Trees has its roots in the 1960s, with early applications in decision analysis and statistics. Notably, J. Ross Quinlan developed the ID3 algorithm in 1986, which laid the foundation for subsequent algorithms like C4.5 and C5.0.
These developments significantly advanced the use of Decision Trees in machine learning and data mining.
Evolution
Over time, Decision Trees have evolved to address limitations such as overfitting and handling continuous variables. Enhancements include:
Pruning Techniques: To reduce overfitting by removing branches that have little predictive power.
Ensemble Methods: Combining multiple trees to improve accuracy, as seen in Random Forests and Gradient Boosted Trees.
Handling Missing Values: Implementing strategies to manage incomplete data effectively.
These advancements have expanded the applicability of Decision Trees across various complex scenarios.
Significant Use Cases
Healthcare: Diagnosing diseases based on patient symptoms and test results.
Finance: Assessing credit risk and making loan approval decisions.
Marketing: Segmenting customers and predicting purchasing behavior.
Operations: Streamlining processes and improving decision-making efficiency.
Use Case Categories
Healthcare & Medicine
Finance & Banking
Marketing & Sales
Operations & Logistics
Human Resources
Sample Use Cases and Step-by-Step Guide
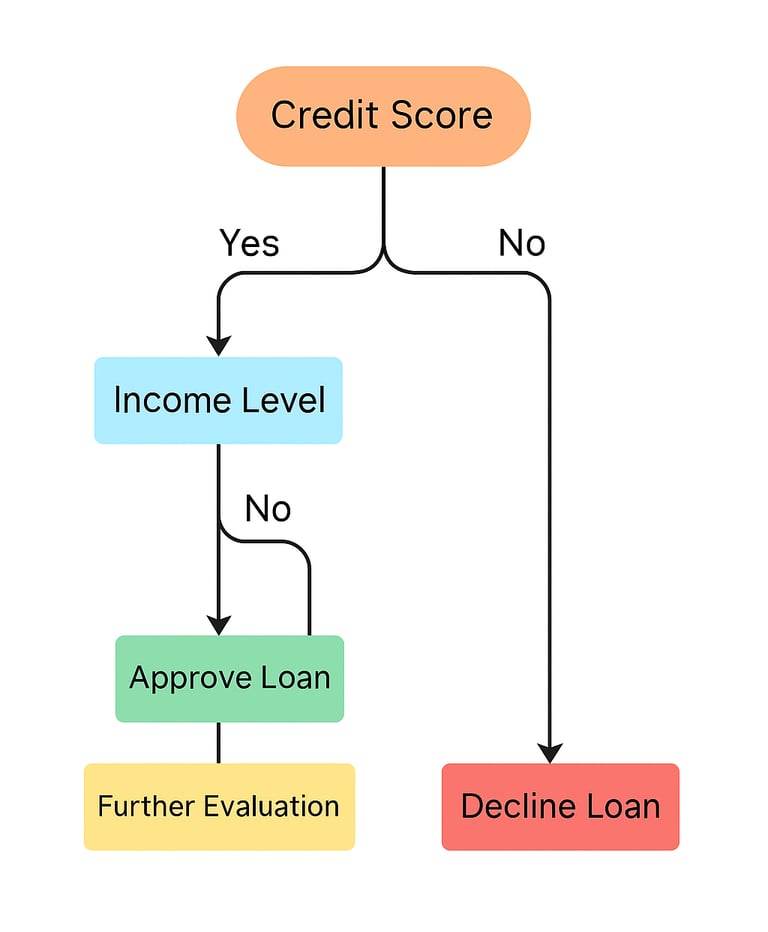
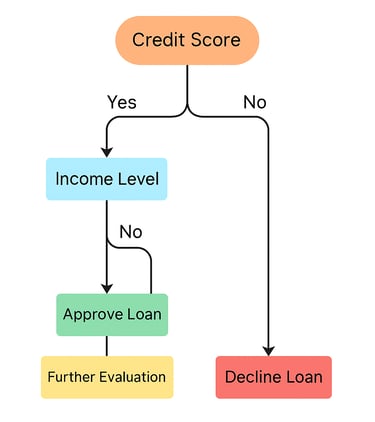
Scenario: A bank wants to determine whether to approve a loan application.
Step 1: Define the Decision Criteria
Applicant's credit score
Income level
Employment status
Existing debts
Step 2: Construct the Tree
Root Node: Credit Score
If >700: Proceed to Income Level
If >$50,000: Approve Loan
Else: Further Evaluation
If ≤700: Decline Loan
Step 3: Analyze Outcomes
Visualize the tree to understand decision paths.
Use historical data to validate the model's accuracy.
Decision Design Lab Interpretation
At Decision Design Lab, we perceive Decision Trees as a bridge between data-driven analysis and intuitive decision-making. Their hierarchical structure mirrors human reasoning, allowing for transparent and justifiable decisions. By integrating Decision Trees, we aim to enhance clarity and confidence in complex decision scenarios.
Scholarly Links
Top-down induction of decision trees classifiers, a review"
– Mach Learn (2000), Lior Rokach & Oded Maimon Link (SpringerOpen)"Decision trees for business intelligence and data mining"
– Book by Lior Rokach and Oded Maimon Chapter Preview"A Unified Approach to Interpreting Model Predictions"
– Lundberg & Lee (SHAP values, used to explain tree-based decisions) arXiv PDFCART: Classification and Regression Trees
– Original paper by Breiman et al. (1984) Monograph Reference
Essential Reads & Interpretations
Data Mining: Practical Machine Learning Tools and Techniques by Ian H. Witten, Eibe Frank, and Mark A. Hall
The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
Authors
J. Ross Quinlan: Developed the ID3 and C4.5 algorithms.
Leo Breiman: Introduced the CART algorithm and Random Forests.
Author/Framework Website
Decision Tree Learning - Wikipedia
Video Links
Rich Visuals
Visual Representation
© 2026 Decision Design Lab
An Opteria Y Private Limited Initiative